FTS Is The Workhorse
Four queries against a personal conversation archive
I stopped using ChatGPT when finding old conversations became hopeless. There’s a keyword search function, but the model itself can’t reach into your chat history. You can’t ask it to find all discussions related to your vacation plans, for example.
So I exported my conversation history and built a custom archive called Convex (sort of a contraction of “conversation” and “arXiv”). I expected hybrid search mode (a combination of full-text search (FTS) and semantic search) to be the best way to find old information in the archive. After all, that was why I built the archive in the first place. But I was wrong in a specific and reproducible way.
Let’s say I want to remember what was said about the speed of spaceships in a sci-fi worldbuilding project called Commonwealth of Benota. I might search for “ship speed benota.” Semantic search doesn’t know what to do with a word like “benota,” so it just pulls in results related to ships and speed. FTS, in contrast, doesn’t care about the meaning of the words; it just matches them against strings in the corpus. In a side-by-side comparison, FTS returns better results. FTS respects the project boundary, while semantic chokes and pollutes the hybrid results.
Was this a generalizable result, or was it an artifact of the project boundary? I did some more queries to find out.
A personal archive is a useful search testbed
My ChatGPT history isn’t all code blocks and error messages. There’s quite a bit of worldbuilding and general conversations in there as well. Out of 1608 conversations, 1037 are assigned to projects and 571 are unassigned. Nearly a quarter of the assigned conversations belong to my D&D campaign, Beyond the Skyreach Mountains (235). There’s a substantial second tier that’s split between different personal programming projects (106 conversations, 2 projects) and some worldbuilding projects (54 conversations, 3 projects).
This is a real corpus, not the massive text embedding benchmark (MTEB). MTEB is the standard benchmark for embedding models. It runs on curated, single-genre corpora where queries and source text look alike. A personal chat archive is the opposite: code blocks next to NPC backstory next to casual conversation, with queries that range from exact-token recall to half-remembered paraphrase.
Unlike MTEB where the answers are known, I’m the ground truth for my corpus. I know what I’m looking for and whether the search was successful. If I’m trying to remember whether ships in the Benota setting will make point-five past lightspeed, I know when I’ve found that. Likewise, if I’m trying to remember why I stopped using a finite state machine in a certain project, I’ll know when the search has surfaced that discussion.
An honest aside: I should have logged queries from day one to evaluate this systematically. I didn’t. Reconstructing real queries after the fact is what made me notice this behavior in the first place. Logging would have surfaced it months earlier.
Two theses, one corpus
I performed some additional queries on my archive, which are discussed in detail below, and I found that no search mode is universally reliable. FTS is the workhorse on queries with strong keyword anchors — proper nouns, technical terms, exact phrasings — which covers most of what I actually ask of this archive. Semantic earns its keep on the queries where I can’t remember the right words. But hybrid is consistently the worst of the three options: whichever search mode underperforms on a given query drags hybrid down through RRF, and that happens often enough on this corpus that “hybrid by default” is the wrong reflex. The right reflex is to pick a search mode per query, and on this corpus, that mode is usually FTS.
I also realized that semantic mode doesn’t respect project boundaries. Proper-noun anchors that FTS uses to scope to the right subcorpus are dissolved by embeddings, which place them in a neighborhood with conceptually-adjacent content from unrelated subcorpora. RRF dampens this leakage but doesn’t eliminate it.
Technical design
It’s important to understand that the dataset for this project is a tree, not a list. The export from ChatGPT is a 170MB single-line JSON file. The JSON data is a list of message objects, each of which specifies parent and children messages. From this, I can reconstruct the conversation tree — which branches I went down, where they branch, and so on. Naively flattening this data to single threads would lose quite a bit of content. Moreover, a naive insertion order would break the foreign key constraints. Instead, I walked the tree, kept the branches, and used a topological sort to resolve foreign keys in the parent_id field.
The message history is imported from the JSON export format and stored in a SQLite database. I went with SQLite over Postgres or another technology because it fits the scope of the project. This is a personal archive with a single user. A dedicated database on a server would be overkill. Importantly, SQLite is capable of storing vectors with the sqlite-vss extension. Again, I could have reached for Postgres and pgvector, but the full RDBMS is overkill for a project of this scope. I don’t need a separate server. A SQLite database can be embedded directly in the Docker image, greatly simplifying deployment. The tradeoff, of course, is that this won’t scale to a multi-tenant architecture, but it doesn’t need to. That’s clearly out of scope.
When implementing hybrid search, I did go with the standard solution rather than departing from it as I did with the choice of database. That standard solution is reciprocal rank fusion (RRF) with k=60. Cross-mode score calibration is a rabbit hole no one needs to enter. RRF sidesteps it by working with rank positions instead of raw scores. I believe in using the right tool for the job, and sometimes the right tool is the thing everyone is doing.
Evidence: Four queries across three search modes
I performed four different queries on my personal corpus. The queries span both technical and worldbuilding projects and have varied ground truths.
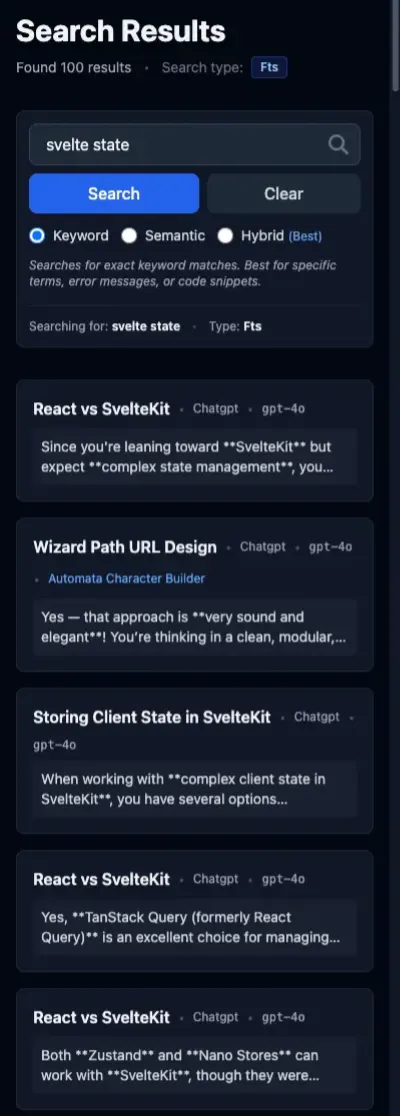
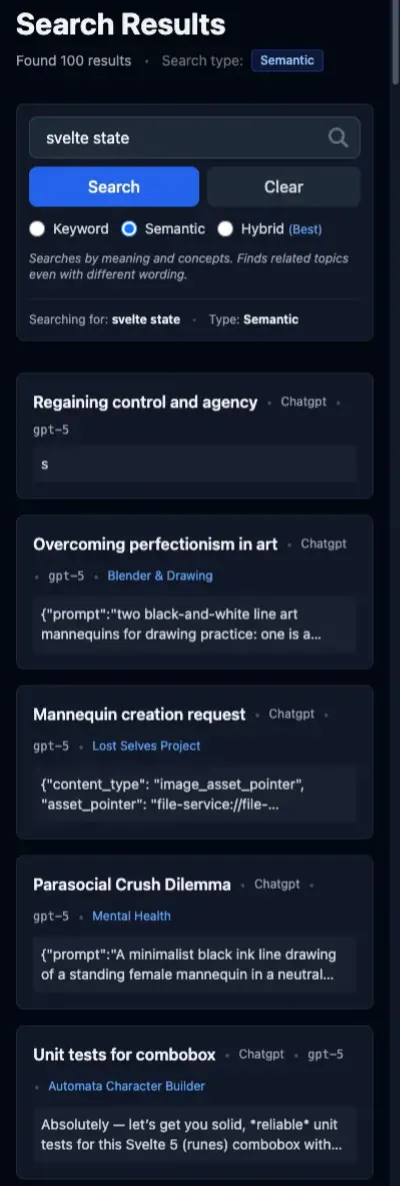
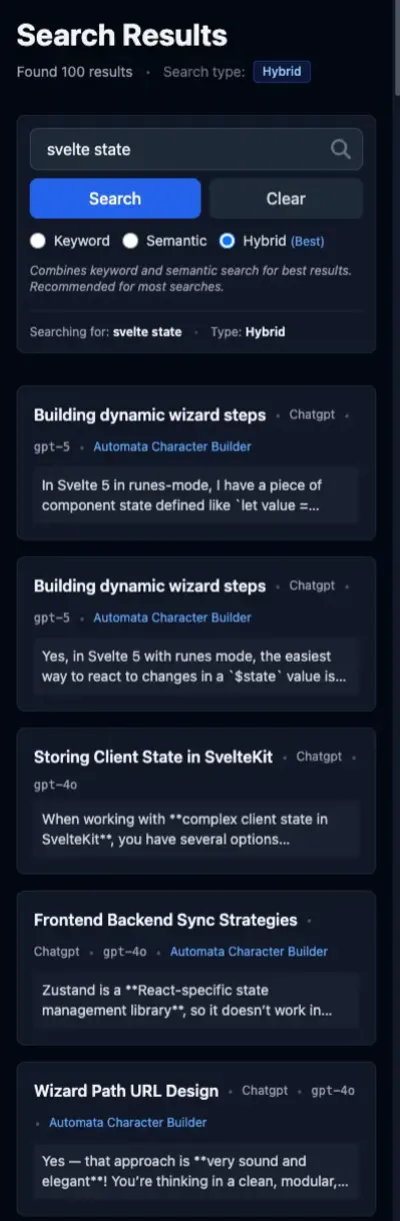
Query: “svelte state”
In my Astro projects, I usually reach for Svelte for interactivity. In more conventional full stack applications, Svelte is my go-to framework for the frontend. I knew that I implemented state management in a few different projects, and I wanted to see how that would be reflected in the search results.
The semantic results for this query are just trash. The first one is a single-letter message, and the next two are attachments. None of these messages have anything to do with state management in Svelte.
The FTS results, in contrast, are all about Svelte state management in some form.
For the hybrid search, the first, second, and fourth results don’t appear in either solo search mode; the remaining ones are drawn from the FTS search. In terms of overall quality, semantic is dragging hybrid down rather than providing the best of both worlds.
Click any to enlarge
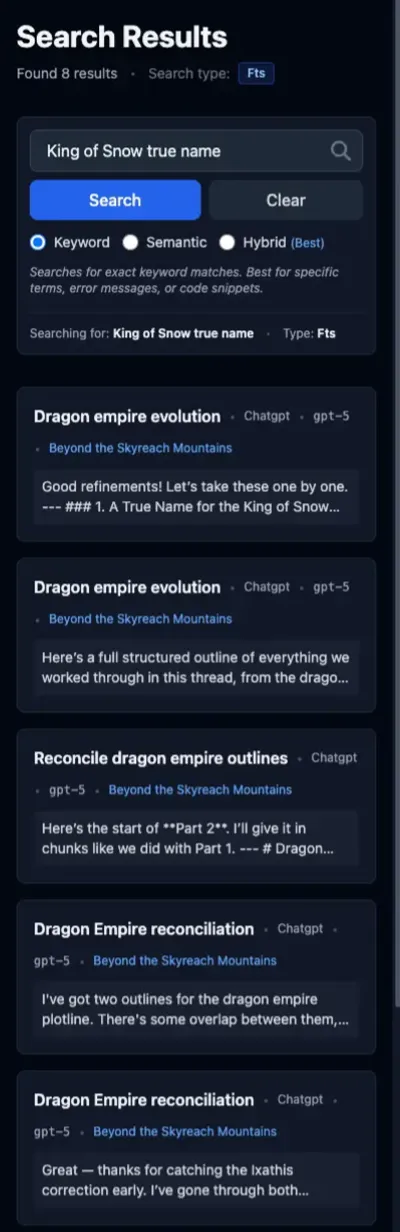
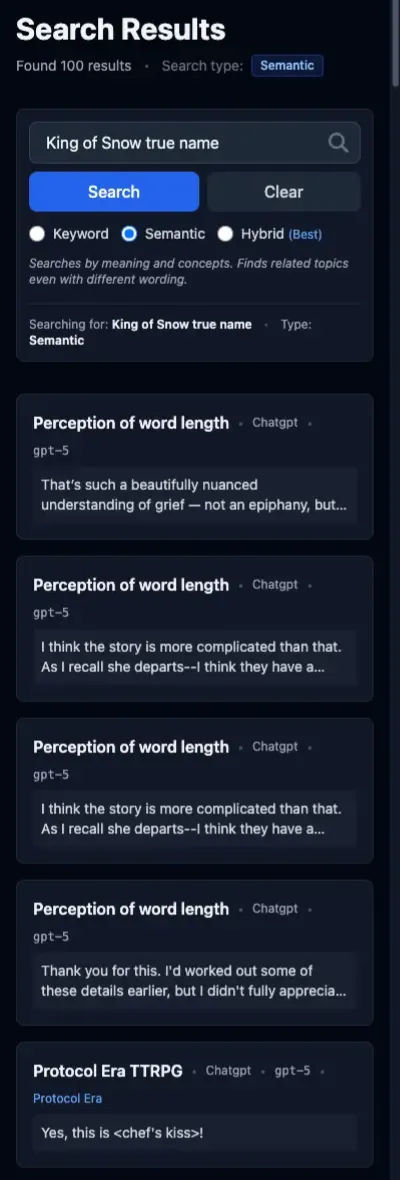
Query: “king of snow true name”
The King of Snow is a non-player character (NPC) in my Dungeons & Dragons campaign. He does have a real name, but so far, the players only know him by his epithet. I wanted to see how well the search functions would help me find his real name in case I ever forgot it (or more likely, its exact spelling).
Semantic search surfaces four messages from the same conversation, plus one from a completely different project. The fifth one is obviously trash, and the first four aren’t great because the NPC’s true name isn’t actually used in that conversation at all. None of the results provide the information I want.
Interestingly, semantic search gives different results for “King of Snow true name” and “king of snow true name”. The all-lowercase version is actually worse as it pulls in several unrelated conversations (not shown).
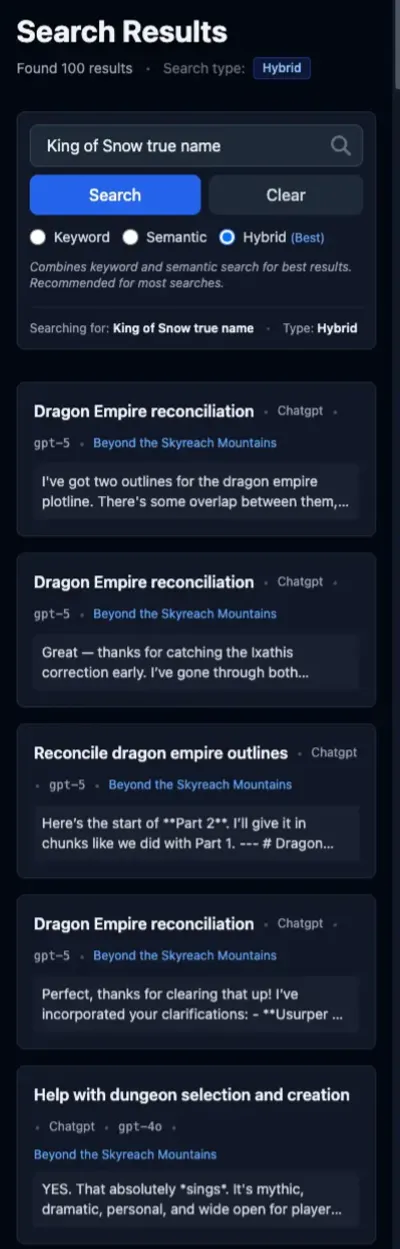
FTS nails it in one. You can see that in the preview for the first result.
Again, semantic search is polluting the hybrid results. That first result from the FTS search, the one that is clearly the correct answer, doesn’t appear anywhere in the top five.
Click any to enlarge
Query: “ship speed benota”
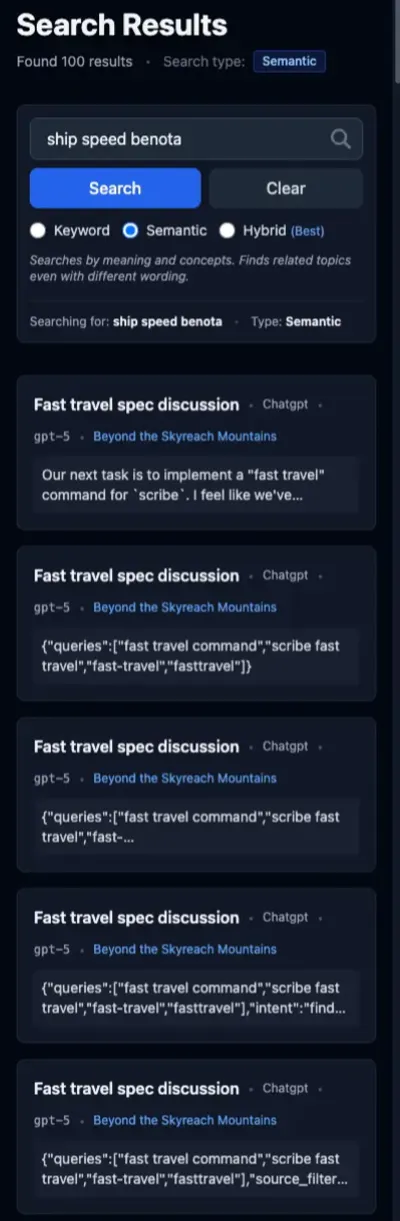
This is the original query that got me thinking about search performance. As I mentioned earlier, Commonwealth of Benota is a sci-fi worldbuilding project in my corpus, and this query is trying to uncover how fast spaceships travel in that setting.
All five results from the semantic search are from the wrong project, full stop. Based on these hits, there’s no way for the semantic search to return the correct result, probably because it doesn’t know what to do with a proper noun like “Benota.”
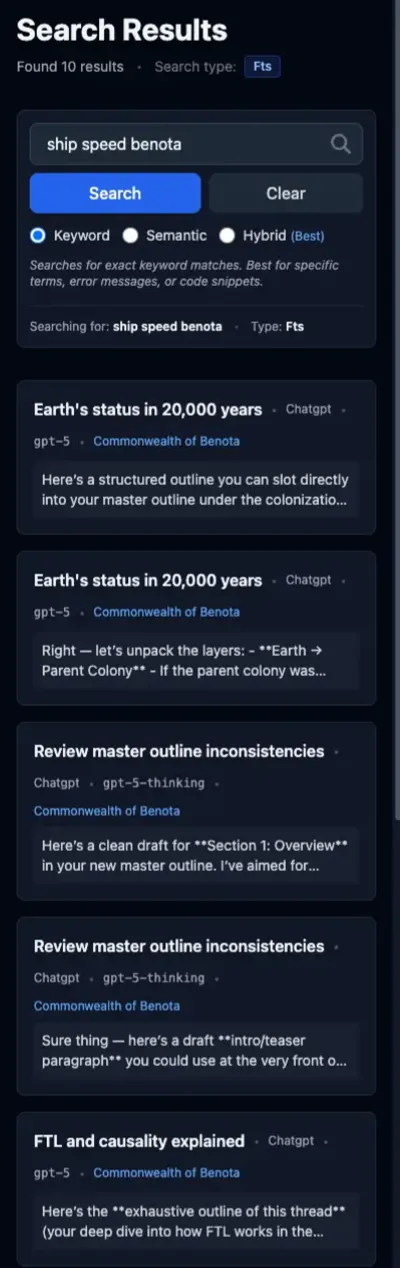
Meanwhile, that search term anchors FTS in the correct project. All three threads it returns discuss ship speed in some capacity, so these results are excellent.
As expected, the hybrid result mixes results from the individual search modes. Hybrid happens to select three good results from FTS plus two bad ones from semantic.
Click any to enlarge
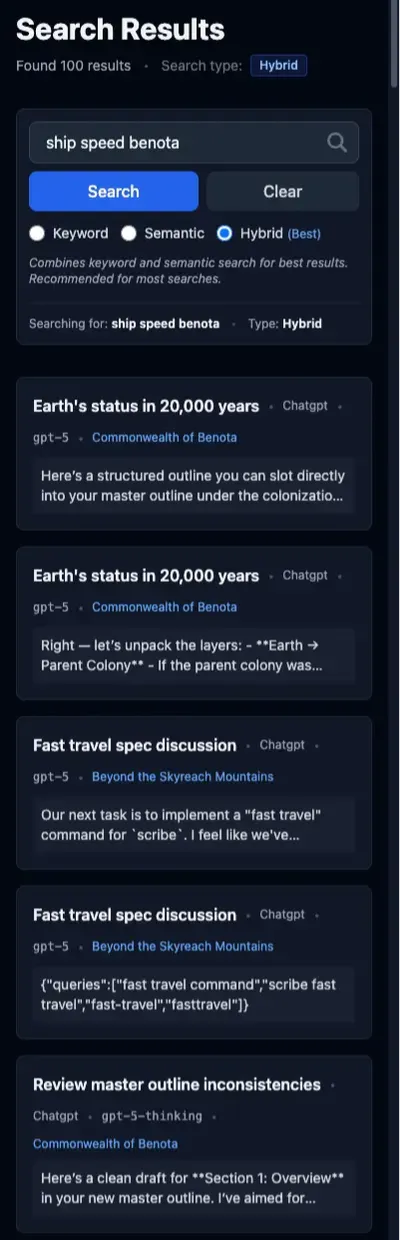
Query: “decision to remove the state machine”
This query is a bit more of a shot in the dark than the others. I knew I had used a finite state machine (FSM) in some project, and I was pretty sure I decided at some point to get rid of it. I could not, however, recall exactly which project it was or why I had made that decision.
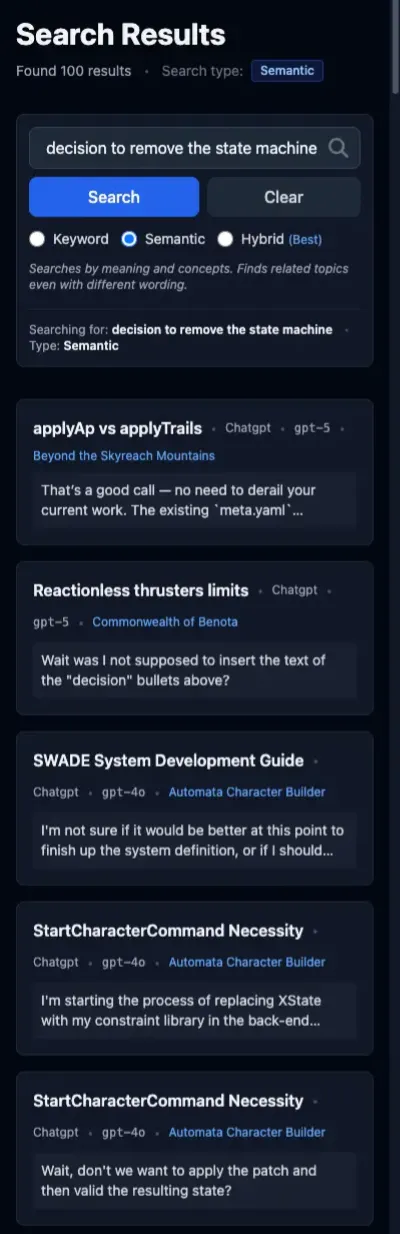
Semantic search actually does okay on this one. The first two results are from worldbuilding projects and are obviously wrong, but the next three are from the “Automata Character Builder” project. This is, I recall, the project that used the FSM, so this is a promising result. The excerpt from the fourth result even shows, “I’m in the process of replacing XState [an FSM library]…” Very encouraging.
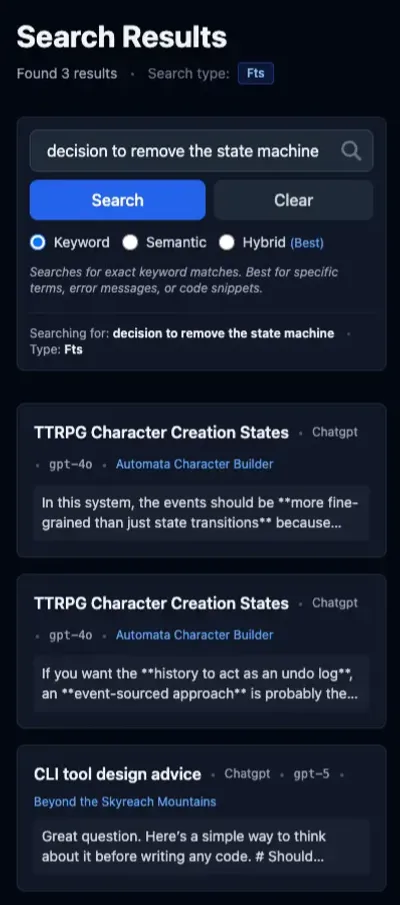
FTS, in contrast, falls down on the job with this query. Only three results total, and only two from the correct project. The “TTRPG Character Creation States” thread, however, is really about the decision to use a FSM, not the later decision to remove it.
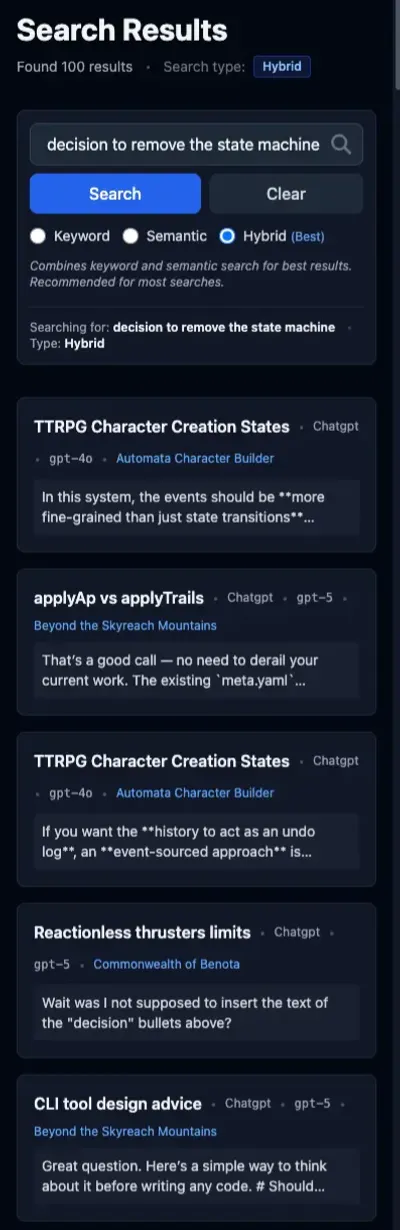
Hybrid again is the result of its inputs. In contrast to the previous searches, the hybrid results are polluted in this case by the FTS results. This pushes the correct result, which is the “StartCharacterCommand Necessity” thread, out of the top five.
Click any to enlarge
Why RRF behaves the way it does
Reciprocal rank fusion (RRF) computes scores roughly as “sum over search modes of 1/(60+rank)”. A result at FTS rank 1 with no semantic ranking scores ~0.0164. A result at FTS rank 4 plus semantic rank 10 scores ~0.030 — almost 2x higher. RRF rewards consistency across search modes and penalizes confident asymmetric signals. It assumes both search modes are roughly competent on every query.
For complex queries on a real-world corpus, however, that assumption breaks. On the searches I’ve discussed here, often FTS and semantic return completely different lists, so RRF struggles to find the commonality between them. If the correct result is the fourth item in the FTS list, for example, it gets pushed out of the hybrid top-5 if RRF interleaves the results. Oftentimes, semantic search is much less competent than FTS, but because RRF treats them equally, the crappy results get ranked alongside the good ones.
It’s important to note that this is not a bug. RRF is working correctly. I’ve just broken its assumption, so I’d expect that performance is pretty poor in an absolute sense. And that’s exactly what the queries show.
Conclusions
On a curated corpus like MTEB, hybrid search does well because it’s optimized for the demo case. Queries are standardized. Results are known. That’s what makes it a useful benchmark.
On a real world corpus, however, hybrid search is the worst of both worlds. In the example above, one search mode or the other dominates. Usually, that’s FTS, but there is one example where semantic search does all the lifting. The hybrid results, which rely on RRF to merge results from both search modes, are dragged down by the underperforming mode.
These results illustrate that the correct search mode depends on the underlying corpus and the query itself. The default search mode for a given corpus should be selected based on testing and empirical data, not hype, trends, or even best practices. My personal corpus, the one that was used in this testing, is highly heterogeneous. More homogenous corpora may benefit more from semantic or even hybrid searching.
On a personal note, this was a fun and successful project that I put together in less than a week, thanks to Claude Code. Model vendors will continue to change — I’d be surprised if I don’t switch from Claude to some other model within the next year or so. The conversations where I worked out my best ideas don’t change and shouldn’t have to. Convex allows me to continue to access them even after changing vendors.