The Correct Number of Retries is One
AI engineering is building reliable systems around an unreliable, non-deterministic component with weird failure modes. Retrying is a critical component in system reliability, but how many times do you retry? The conventional wisdom from distributed systems engineering says to use an unlimited number of retries with an exponential backoff. That, however, doesn’t consider the weird failure modes of an LLM, so the conventional wisdom doesn’t hold. The correct number of retries is one.
Exactly one retry. Not unlimited, not a budget, not even three — one.
More specifically, when a model’s structured output fails validation, you should retry exactly once with the rejection inlined as a tool error; if the second attempt also fails, throw an error and roll back the transaction. A second failure means the problem is your validator, your prompt, or your schema — not the model. Compounding retries hides where the true problem is, and it only serves to run up your bill.
Enter Zoltar
Zoltar is an AI game moderator (GM) for solo tabletop roleplaying games (TTRPGs). Its game state lives server-side, and Claude proposes state changes through validated tool calls. Here is a simple sequence diagram showing the initial call to the LLM and its response, which fails validation. After the failure, there’s a retry and the LLM’s second response. The second response passes validation.
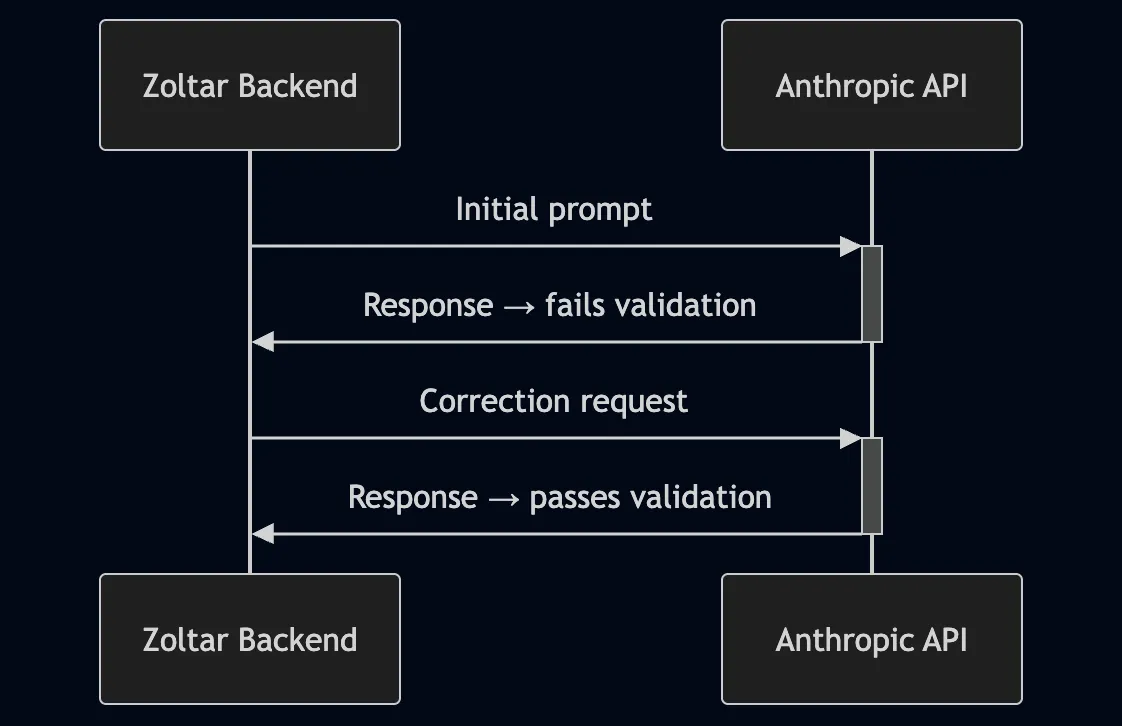
The initial prompt sent to Claude includes the current game state. The game state includes the current hit points (HP) of non-player characters (NPCs). HP are essentially a measure of how much “life” a character has left before they die.
Here’s a JSON representation of the game state. The actual prompt wraps this in XML tags for the model to view as authoritative state; the JSON is the underlying shape.
{
"entities": {
"dr_chen": { "visible": true, "status": "alive" }
},
"resourcePools": {
"dr_chen_hp": { "current": 4, "max": 10 },
"dr_chen_stress": { "current": 4, "max": null }
},
"flags": { ... },
"scenarioState": { ... },
"worldFacts": { "ship_name": "Callisto" }
}
Claude proposes state changes by calling a submit_gm_response tool. A validator in the backend accepts or rejects each change. Claude’s response might look like:
{ "stateChanges": { "resourcePools": { "dr_chen_hp": { "delta": -9 } } }, ... }
The validator checks this submission against the current state. dr_chen_hp is at 4/10, and resource pools default to min: 0. The -9 delta gets rejected because it would drop the pool below that default minimum.
The correction loop builds a follow-up request. The backend server uses a buildCorrectionRequest function to assemble the follow-up. After extracting the original tool-use block from inside the rejected response, the rejection details get formatted into a tool_result content block:
const rejectionText = args.rejections
.map((r) => `- ${r.path}: ${r.reason}`)
.join('\n');
const toolResultBlock = {
type: 'tool_result',
tool_use_id: toolUseBlock.id,
is_error: true,
content: [
{
type: 'text',
text:
`The backend rejected ${args.rejections.length} proposed state change(s):\n\n` +
`${rejectionText}\n\n` +
`Re-narrate this turn. Call submit_gm_response again with corrected ` +
`stateChanges that the backend will accept. Keep the narration faithful ` +
`to the fiction — if an action is impossible, describe why in character ` +
`rather than silently dropping it.`,
},
],
};
The original assistant message stays in the history, and a new user message carries a tool_result block pointing at the original tool_use_id with is_error: true:
{
"type": "tool_result",
"tool_use_id": "toolu_01...",
"is_error": true,
"content": [{ "type": "text", "text": "The backend rejected 1 state change: ..." }]
}
The request also narrows tool_choice to force a direct resubmit.
{
"model": "claude-sonnet-4-6",
"messages": [ ... ],
"tool_choice": { "type": "tool", "name": "submit_gm_response" }
}
The toolResultBlock is then combined with the original request to assemble the complete correction request. The prompt specifically tells the model to narrate the result, whether it’s good for the player or not. This is true to how real GMs handle failure in TTRPGs, but it’s not second nature to LLMs.
Finally, Claude sends a second response, which is again run through the validator. If it passes, everything is copacetic. If it fails, the backend logs the error and notifies the user.
Technical Evidence
When I first started thinking about this problem, I reached for other unreliable components with standard solutions. I realized that flaky tests are similar to LLMs. When a flaky test goes belly up, it should fail loudly rather than rerunning itself. The same logic applies to an LLM. Since I’m trying to build a reliable system around the LLM, I want to follow the same pattern: fail loudly and early.
There’s an old tech-support story from the 1990s, back when desktops were the norm: a customer calls in because their computer won’t start. After half an hour of troubleshooting, the support tech finally realizes that the customer has lost power to their home, and it’s not actually a problem with the computer at all. The error that gets surfaced is hiding an error elsewhere in the system.
For example, an early iteration of the validator automatically set hit points (HP) to 0 if Claude flipped an entity’s status from “alive” to “dead.” This update kept the data internally consistent, but it papered over an inconsistency in Claude’s response. In contrast, the current validator rejects if HP isn’t zeroed when the status changes to “dead.” This forces Claude to make its response internally consistent. One retry is enough for Claude to fix that. If this validation rule rejected repeatedly on the same turn, it’s like flipping the power switch on your computer repeatedly. Nothing is going to work if there’s not electricity flowing to the computer. Instead, the repeated failure indicates that the problem lies elsewhere in the system.
Repeatedly flipping the power switch is cheap, so you can do it multiple times at basically zero cost. Calling the LLM is expensive, so only do it once.
The exact problem and its solution are not always obvious, however. Finding them may require some experimentation. For example, I might update the validator to restore the automatic zeroing behavior. If that solves the problem, great. If Claude continues failing after one retry, then I might roll back that change and try something else.
I may decide that it’s preferable to tighten the schema to make the invalid state impossible as a function of the schema itself — not just a validation rule. This is like baking a validation into your static types, so it gets surfaced at write-time, rather than leaving it in a run-time check. The run-time check surfaces the error much later when it’s more costly to fix.
Alternatively, the problem may lie in the prompt itself. I could tighten the language in the prompt that requires Claude to zero HP when an entity dies. Same schema, same validation rules, just an updated prompt.
The takeaway is that the need for these changes is surfaced by the hard cap on retries. If the validation rule rejects twice on the same turn and then gets the answer right on the third try, that’s not the model learning or correcting its behavior. It’s just the model’s random nature getting it right by chance. It’s the right answer but for the wrong reason. Most importantly, it hides the need to make changes to the system.
Alternative Approaches to Error Handling
There are several other approaches to handling validation errors that I considered and then rejected. My guiding principle for this analysis is that the model non-deterministically passing validation isn’t success — it’s a silent error.
Unbounded Retry with Backoff
When your network goes down, Gmail tries to reconnect. Then it waits 4 seconds before the next retry, then it waits 8 seconds, then 16, and so on, until Verizon fixes the outage. This is an unbounded retry with exponential backoff. It’s the standard approach to transient failures and is exactly the right move for transient failures, like network outages. But it’s wrong for semantic failures, which will continue failing until they eventually succeed based on chance alone.
N-shot Retry Budget
This is like the Gmail example, but with a cap. “Only retry 6 times,” or something like that. It’s better because it doesn’t give the model an essentially infinite amount of time to guess a correct response. It’s not good in that the model still has multiple chances to get one right by accident.
No Retries
This is a totally valid choice! The problem is that models sometimes make dumb formatting errors, like putting leading spaces in field names. Semantically, it’s just fine, but the validator doesn’t like it one bit. Surfacing errors to users just because the model wrote " resourcePools:" instead of "resourcePools:" is not something I want Zoltar to do. If you have production data that says a first failure always results in a second failure, then capping retries at 0 is the smart and budget-friendly move.
When the Rule Doesn’t Apply
There is one scenario where you may want to ignore or at least modify the advice in this article. If the validator’s rejection is not a pure function of the model’s response, then you may want a different number of retries. For example, your state may depend on some external signal that can change between LLM calls. In this case, you probably want to retry more than just once. Consider capping it at one retry per identical state. When the state changes, reset the retry counter.
Conclusions
The number of retries you allow is a statement about where you think failures are coming from. If it’s a transient failure, you’re safe with a retry backoff loop. If it’s a pure-function validator against structured output from an LLM, the correct number of retries is one.
Surface failures to make models and agents more reliable. Make it easy to determine which component and which layer failed. Retry budgets and unlimited retries work against that.